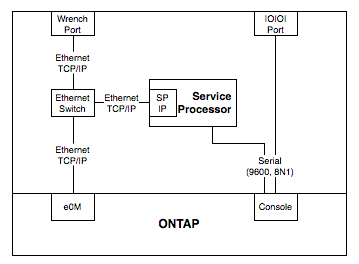
One of the things I’ve seen new (and sometimes existing..) customers to NetApp be most confused about, are the various ways of connecting to the system for management.
Over the years, there have been a couple of different out of band management systems (RLM and BMC are the older systems, SP on the newer ones). This post focuses on systems with Service Processor, or SP, as used in the FAS2200, FAS2500, FAS3100, FAS3200, FAS6100, FAS6200 and FAS8000 families. Lets start by going through the physical ports on the back of the controller. Where the ports are varies slightly by model, but the icons are consistent.
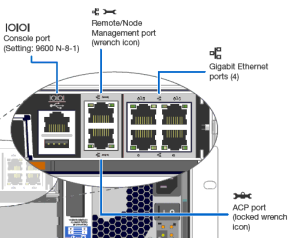
A common question is “ok, so the wrench port is e0M, why doesn’t it just say that?”. The short answer is that it isn’t – although you could be forgiven for making that guess. Even NetApp’s label set for Clustered ONTAP includes an e0M cable label, despite their systems not having a specific port labelled e0M. Let’s look at how the ports connect up, from the point of view of an administrator:
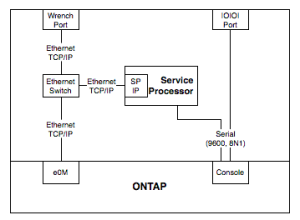
From this simplified block diagram, you can see how they all relate. The port on the outside of the box actually connects to a switch inside the box, and that has both ONTAP’s e0M and the Service Processor’s IP interface connected to it. It’s almost literally running Ethernet on the motherboard traces (it’s actually something called RMII, not normal 802.3, but close enough). The internal switch is unmanaged, which is why you can’t do VLANs over that port. To clarify some more – the service processor is an independent CPU, with its own RAM, flash and OS running on it. It talks to ONTAP very closely, obviously, and to sensors throughout the system, but it’s separate to the main kernel running on the x86 CPU that runs ONTAP.
On 7-mode systems, e0M is just another interface in ONTAP, but in Clustered ONTAP, it can only be used for management LIFs, not data LIFs (or Cluster LIFs). On the FAS2500 and FAS8000, the wrench port, and therefore e0M, are finally 1G, but on previous systems, it’s only 100M. On 7-mode systems, you have to be careful – you don’t want it on the same subnet as any of your data service IPs, or traffic might go out through it, instead of a 1G or 10G port. To stop this, set “options interface.blocked.mgmt_data_traffic on” for all systems (running ONTAP 8.0.2 or higher), but ideally put it on a different subnet. It’s best practice to have, at the very least, a different OOB subnet to data services.
From our diagram again, if you need to do something like monitor boot/shutdown/reboot during an ONTAP upgrade, you can either connect to the Serial Console or the SP IP – the output is the same. I’ve done lots of remote upgrades this way. Once the system is up, and the SP is configured, there’s almost never a need to use the Serial Console again. The SPs don’t talk to each other, so if one node is online and the other is offline, you can’t use the online node to connect to the offline one.
If you’re the type who like managing your 7-mode NetApp from the command line, you would normally SSH into the e0M IP address, while for Clustered ONTAP, you would normally SSH to the Cluster Management IP. You could go from the SP to the system console, but that will be limited to 9600bps output through the serial connection, and if you’re looking at a lot of text, or pasting a lot of text, that can be limiting. For using GUI applications like OnCommand System Manager, you connect to the e0M IP on 7-mode, and the Cluster Management IP on Clustered ONTAP Systems.
A final question I’ve heard is “what is that USB port for?”. Officially, for regular users, it’s unsupported. Unofficially, you can use it to charge your iPhone while its running in hotspot mode, or to power your Airconsole.
Could this all be made simpler? Well, there are good purposes for all of the different IPs and interfaces you might use, so I’m not 100% convinced it could be. Everything new is complex initially, but once you get a handle on it, it all makes sense. Hope this has helped you!
Edit: 2018-07-11
Since writing this article, we’ve released some new platforms, which enable the USB port while at the boot menu, have faster serial ports, and move from an SP to a BMC. They’re pretty similar, except the BMC doesn’t tap into a serial link to the ONTAP controller – it relays it over an internal network, and it doesn’t share the wrench port with e0M anymore.